目录
让我们学习AI,拥抱AI,一起迎接AGI的到来,共同见证AI改变世界。
笔记内容基于《知学堂AI大模型全栈工程师》课程
AGI
AGI(Artificial General Intelligence) 通用人工智能,什么时候到来?
行业中:
乐观预测:明年(不太靠谱)
主流预测:3-5年
悲观预测:10年
AGI时代,将会行成新的社会分层:
- AI使用者,就是使用别人开发好的AI产品(人人都在用)
- AI产品的开发者,设计和开发AI产品
- 基础模型相关,训练基础大模型或者为大模型提供基础设施(基础模型相关门槛特别高,机会特别难遇到。比如:全球做基础大模型训练的只需要1000人)
AI产品开发者的核心能力
首先,三懂
- 懂业务:要懂用户、懂客户、懂需求、懂市场、懂运营、懂商业模式
- 懂AI:懂AI能做什么、不能做什么,怎样才能做得更好、更快、更便宜
- 懂编程:懂如何通过编程实现一个符合业务需求得产品
争取三懂,至少两懂,任何人无论如何要懂AI。所以有三种人:
- AI全栈工程师:懂业务、懂AI、懂编程
- 业务方向:懂业务、懂AI
- 编程方向:懂编程、懂AI
建议:
编程向的,要尽可能靠近业务,争取全栈,否则走不远
业务向的,试试学编程,自主性更强。AI 编程,门槛已经低多了(但绝不是没门槛)
大模型 AI 能干什么?
大模型,全称「大语言模型」,英文「Large Language Model」,缩写「LLM」。
以下是基于大语言模型下的对话产品和对应试用的大模型:
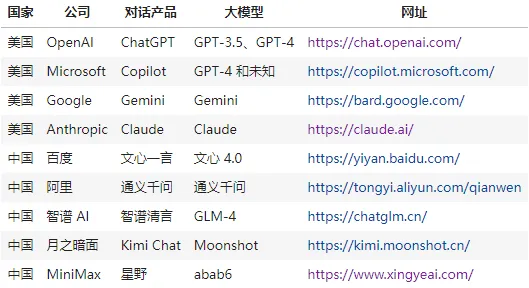
大语言模型绝不只是聊天机器人,它的能量远不止于此。
如果业务中存在输出、分类、聚类、持续互动等场景,都适合使用大模型,甚至任何场景。
从程序员的角度思考,大模型就是一个函数,给输入生成输出;任何可以用语言描述的问题,都可以输入给大模型,就能生成结果。
大模型是怎么生成结果的
其实,它只是根据上文,猜下一个词(的概率)。

训练和推理是大模型工作的两个核心过程;用人来类比,训练就是学习,推理就是运用。
训练:
大模型阅读了人类说过的所有的话。这就是「机器学习」
训练过程会把不同 token 同时出现的概率存入「神经网络」文件。保存的数据就是「参数」,也叫「权重」
推理:
我们给推理程序若干 token,程序会加载大模型权重,算出概率最高的下一个 token 是什么
用生成的 token,再加上上文,就能继续生成下一个 token。以此类推,生成更多文字
Token是什么?
可能是一个英文单词,也可能是半个,可能是一个中文词,或者一个汉字,也可能是半个汉字,甚至三分之一个汉字
大模型在开训前,需要先训练一个 tokenizer 模型。它能把所有的文本,切成 token;所以说大模型处理的单位就是token
很多中文的大模型会把一个字甚至一个词当成一个token,而在openai英文为主的大模型通常是把汉字分成2个token。所以在中文大模型中一个token通常代表1到1.5个汉字,而在英文模型里边可能需要1.5到2个token才能代表1个汉字;所以一般情况下中文的大模型处理的速度要比英文的大模型要高成本要低。
这套生成机制的内核叫[Transformer架构]。Transformer是主流的,但是不是最先进的。

用好AI的核心心法
把AI当人看
和人怎么相处就和AI怎么相处。学习的时候把AI当老师,工作的时候把AI当助手,休闲的时候把AI当朋友。
大模型应用业务架构
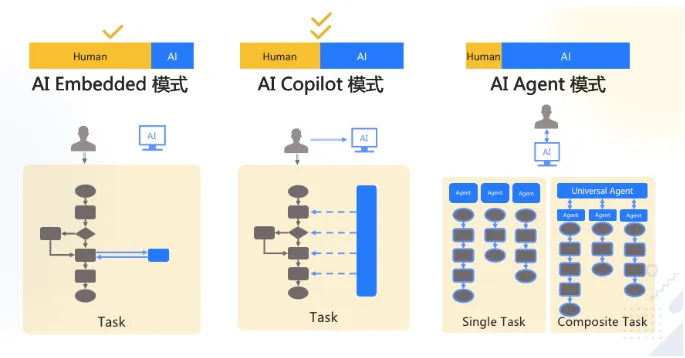
Embedded模式是之前的,Copilot是现在的比较主流的,Agent 还太超前。业务中最关键的是呀理清业务,拆除SOP。
大模型应用技术架构
大模型应用技术特点:门槛低,天花板高。
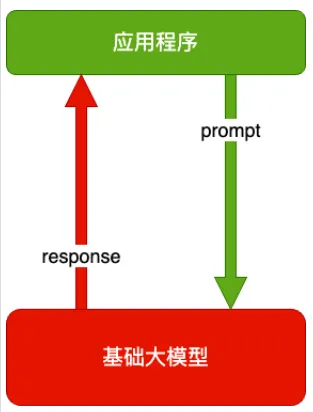
1. 纯 Prompt
当人看:你说一句,ta 回一句,你再说一句,ta 再回一句
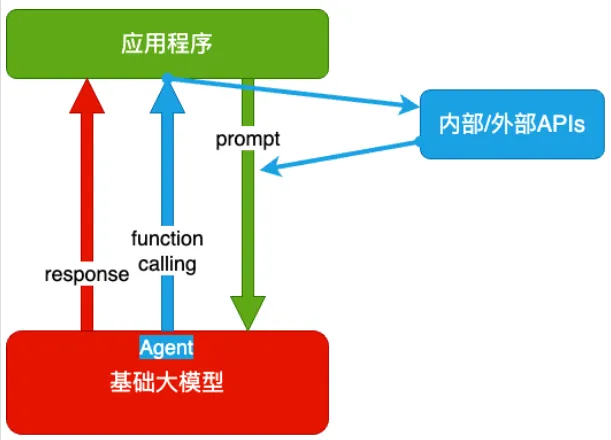
2. Agent + Function Calling
Agent:AI 主动提要求
Function Calling:AI 要求执行某个函数
当人看:你问 ta 过年去哪玩,ta 先问你有多少预算
3. RAG(Retrieval-Augmented Generation)
Embeddings:把文字转换为更易于相似度计算的编码。这种编码叫向量
向量数据库:把向量存起来,方便查找
向量搜索:根据输入向量,找到最相似的向量
当人看:考试答题时,到书上找相关内容,再结合题目组成答案,然后,就都忘了
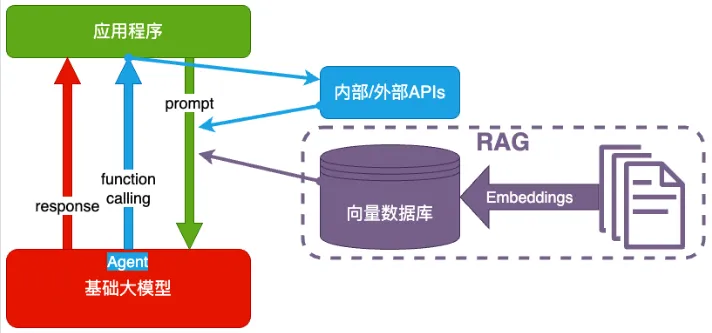
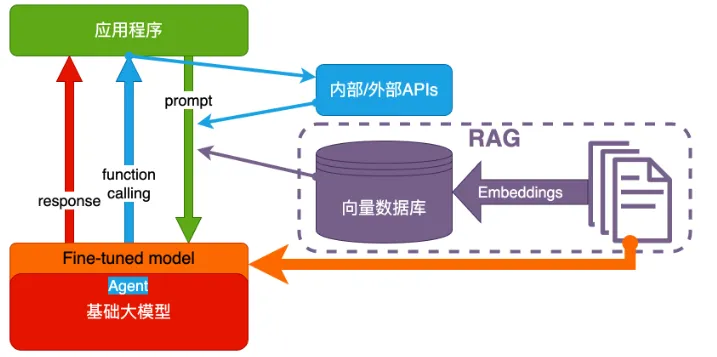
4. Fine-tuning(精调/微调)
当人看:努力学习考试内容,长期记住,活学活用。
如何选择技术路线
下面是个不严谨但常用思路。
最重要的是准备测试数据,用对话应用验证的可行性
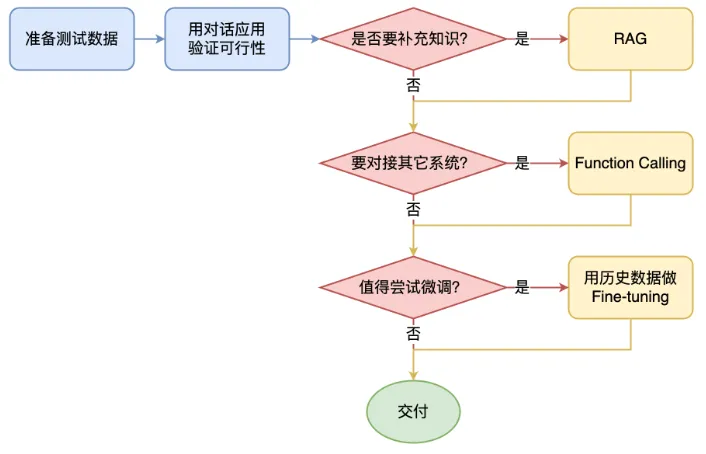
值得尝试 Fine-tuning 的情况:
提高模型输出的稳定性
用户量大,降低推理成本的意义很大
提高大模型的生成速度
需要私有部署
如何选择基础模型
基础模型选型,也是个重要因素。合规和安全是首要考量因素。(没有最好的大模型,只有最适合的大模型)
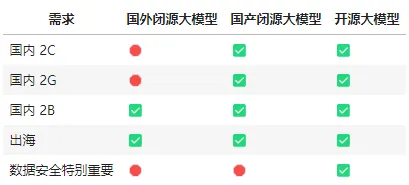
唯一值得相信的榜单:LMSYS Chatbot Arena Leaderboard
本文作者:wucc
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-SA 许可协议。转载请注明出处!